게시글 삭제
정말 삭제하시겠습니까?
CLIP, 텍스트, 이미지 연결
[주요 목차]
CLIP의 기본 개념
CLIP의 작동 방식
CLIP의 활용 사례와 주의사항
안녕하세요! 오늘은 딥러닝의 중요한 요소 중 하나인 CLIP에 대해 알아보려고 해요. CLIP은 텍스트와 이미지를 연결해주는 모델로, 최근 많은 주목을 받고 있거든요. 특히, 기존의 이미지 분류 방식과는 다른 혁신적인 접근 방식을 제공해줘요. 이 글을 통해 CLIP의 기본 개념, 작동 방식, 그리고 실질적인 활용 사례와 주의사항까지 알아보면, 여러분도 CLIP을 실무에서 어떻게 활용할 수 있을지 감을 잡을 수 있을 거예요. 준비되셨죠? 그럼 시작해볼게요!
 CLIP, 텍스트, 이미지 연결 · 핵심 장면 1
## CLIP의 기본 개념
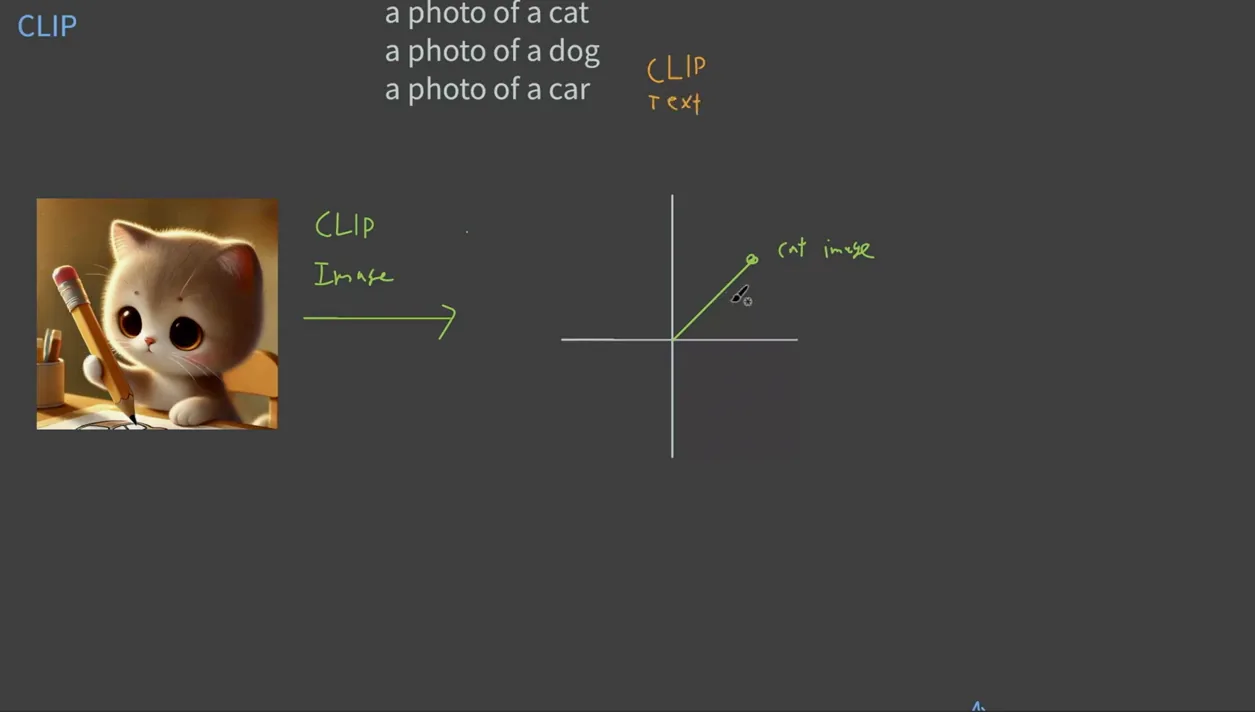
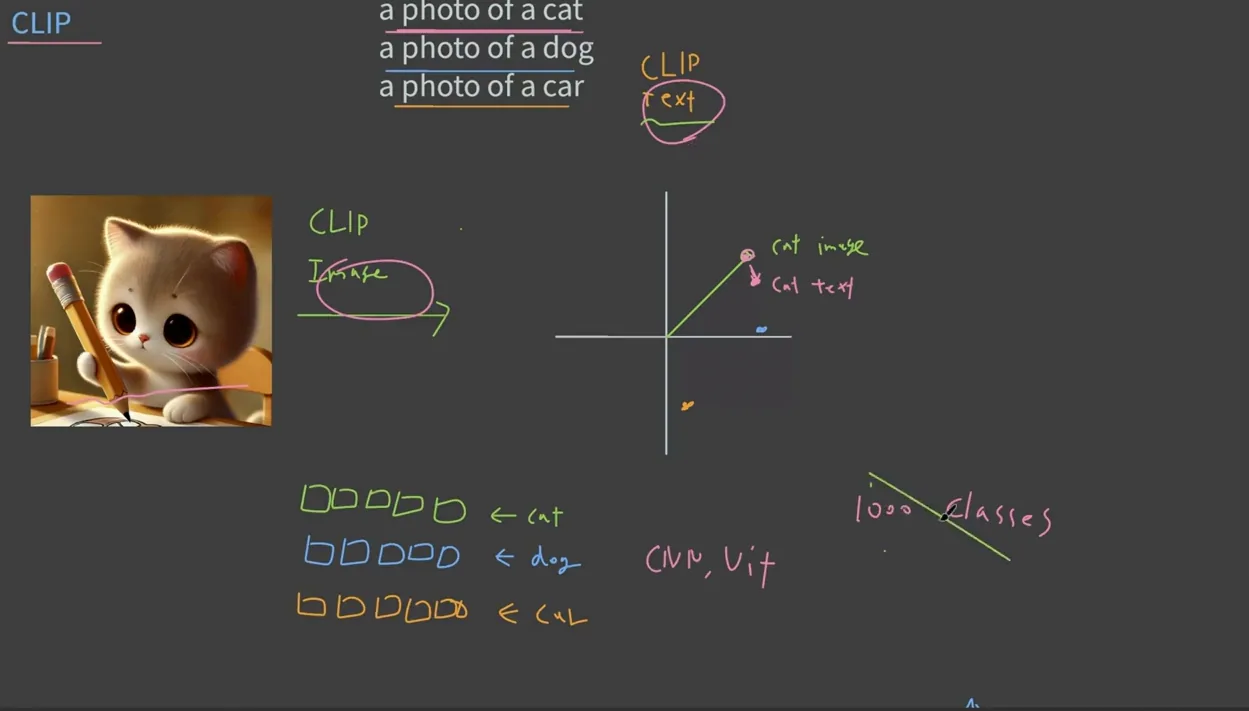
CLIP은 "Contrastive Language–Image Pre-training"의 약자로, 이미지와 텍스트 간의 관계를 학습하는 딥러닝 모델이에요. 이 모델은 텍스트와 이미지를 동시에 입력받아, 이 둘을 임베딩 벡터 공간에서 특정한 포인트로 맵핑해요. 예를 들어, 고양이 이미지를 입력하면, 이를 고양이에 해당하는 벡터로 변환하고, "고양이", "강아지", "차" 같은 텍스트를 입력하면 각각의 텍스트도 벡터로 변환되죠.
이렇게 변환된 벡터들끼리의 유사도를 계산하면, 가장 유사한 텍스트를 찾아낼 수 있어요. 예를 들어, 고양이 이미지와 "고양이"라는 텍스트의 유사도가 높다면, 해당 이미지는 "고양이"라고 분류할 수 있는 거죠. 이 방식은 기존의 이미지 분류 방식, 즉 수천 장의 레이블된 이미지를 준비해야 했던 수고를 덜어주는데요. CLIP은 미리 정의된 클래스에 구애받지 않고, 다양한 텍스트 프롬프트를 통해 이미지를 분석할 수 있는 유연성을 제공해요.
CLIP, 텍스트, 이미지 연결 · 핵심 장면 1
## CLIP의 기본 개념
CLIP은 "Contrastive Language–Image Pre-training"의 약자로, 이미지와 텍스트 간의 관계를 학습하는 딥러닝 모델이에요. 이 모델은 텍스트와 이미지를 동시에 입력받아, 이 둘을 임베딩 벡터 공간에서 특정한 포인트로 맵핑해요. 예를 들어, 고양이 이미지를 입력하면, 이를 고양이에 해당하는 벡터로 변환하고, "고양이", "강아지", "차" 같은 텍스트를 입력하면 각각의 텍스트도 벡터로 변환되죠.
이렇게 변환된 벡터들끼리의 유사도를 계산하면, 가장 유사한 텍스트를 찾아낼 수 있어요. 예를 들어, 고양이 이미지와 "고양이"라는 텍스트의 유사도가 높다면, 해당 이미지는 "고양이"라고 분류할 수 있는 거죠. 이 방식은 기존의 이미지 분류 방식, 즉 수천 장의 레이블된 이미지를 준비해야 했던 수고를 덜어주는데요. CLIP은 미리 정의된 클래스에 구애받지 않고, 다양한 텍스트 프롬프트를 통해 이미지를 분석할 수 있는 유연성을 제공해요.
 CLIP, 텍스트, 이미지 연결 · 실전 화면 2
## CLIP의 작동 방식
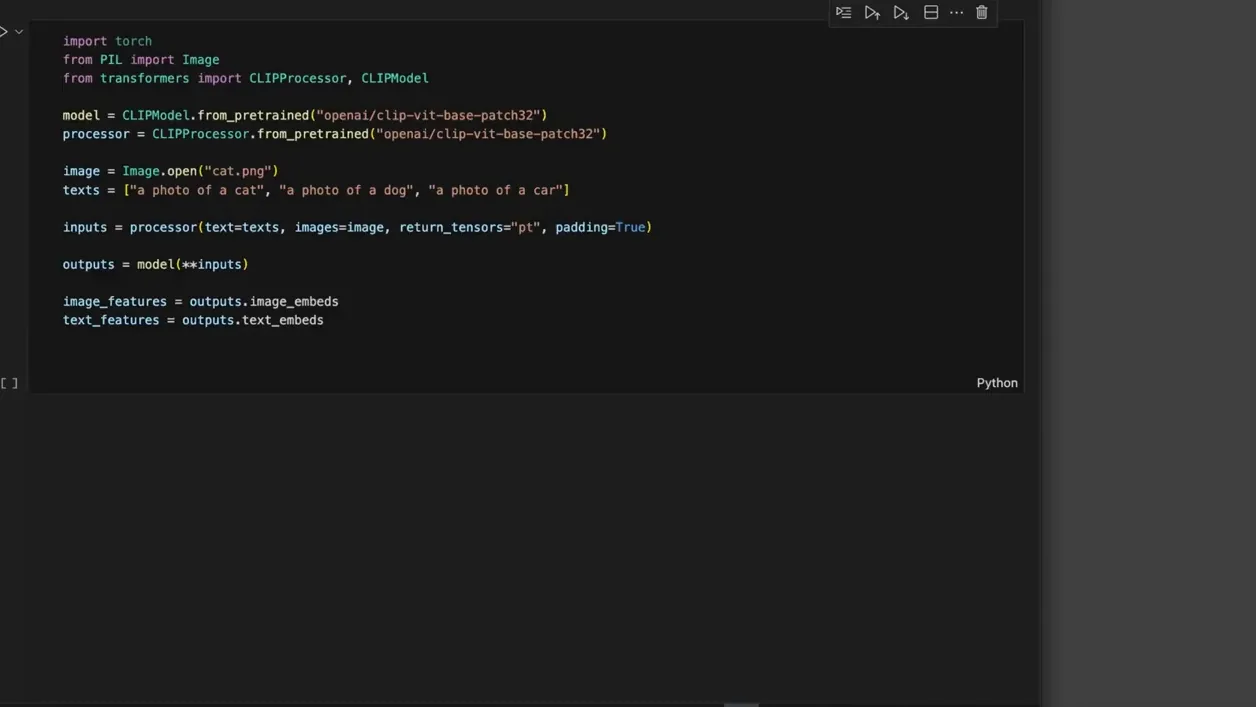
CLIP의 작동 방식은 크게 두 가지로 나눌 수 있어요. 첫 번째는 이미지 인코딩이고, 두 번째는 텍스트 인코딩이에요. 이미지 인코딩은 주어진 이미지를 CNN(Convolutional Neural Network)이나 비전 트랜스포머를 이용해 임베딩 벡터로 변환해요. 예를 들어, 고양이 사진을 입력하면, 이를 512 차원의 벡터로 변환하게 되죠.
반면, 텍스트 인코딩은 주어진 텍스트를 트랜스포머 모델을 통해 처리해요. 텍스트는 시작 토큰과 종료 토큰을 붙인 후, 이를 트랜스포머의 셀프 어텐션 메커니즘을 통해 변환해요. 이렇게 변환된 텍스트도 역시 512 차원의 벡터로 만들어지죠. 최종적으로 이미지와 텍스트는 동일한 벡터 공간에 위치하게 되며, 이 둘 사이의 유사도를 비교할 수 있게 돼요.
이 과정에서 중요한 점은, 이미지와 텍스트가 잘 매치되도록 학습하는 과정이에요. 이를 위해 CLIP은 콘트라스트 러닝을 활용해, 이미지와 텍스트 쌍을 통해 서로를 더욱 잘 이해하게 만들죠. 이 방법 덕분에 CLIP은 다양한 이미지와 텍스트 조합에 대해 유연하게 대응할 수 있어요.
CLIP, 텍스트, 이미지 연결 · 실전 화면 2
## CLIP의 작동 방식
CLIP의 작동 방식은 크게 두 가지로 나눌 수 있어요. 첫 번째는 이미지 인코딩이고, 두 번째는 텍스트 인코딩이에요. 이미지 인코딩은 주어진 이미지를 CNN(Convolutional Neural Network)이나 비전 트랜스포머를 이용해 임베딩 벡터로 변환해요. 예를 들어, 고양이 사진을 입력하면, 이를 512 차원의 벡터로 변환하게 되죠.
반면, 텍스트 인코딩은 주어진 텍스트를 트랜스포머 모델을 통해 처리해요. 텍스트는 시작 토큰과 종료 토큰을 붙인 후, 이를 트랜스포머의 셀프 어텐션 메커니즘을 통해 변환해요. 이렇게 변환된 텍스트도 역시 512 차원의 벡터로 만들어지죠. 최종적으로 이미지와 텍스트는 동일한 벡터 공간에 위치하게 되며, 이 둘 사이의 유사도를 비교할 수 있게 돼요.
이 과정에서 중요한 점은, 이미지와 텍스트가 잘 매치되도록 학습하는 과정이에요. 이를 위해 CLIP은 콘트라스트 러닝을 활용해, 이미지와 텍스트 쌍을 통해 서로를 더욱 잘 이해하게 만들죠. 이 방법 덕분에 CLIP은 다양한 이미지와 텍스트 조합에 대해 유연하게 대응할 수 있어요.
 CLIP, 텍스트, 이미지 연결 · 주요 포인트 3
## CLIP의 활용 사례와 주의사항
CLIP의 활용 사례는 무궁무진해요. 예를 들어, 이미지 검색 엔진에 적용할 수 있어요. 사용자가 특정 텍스트를 입력하면, 해당 텍스트와 가장 유사한 이미지를 찾을 수 있도록 도와주는 거죠. 또한, 소셜 미디어에서의 콘텐츠 추천 시스템에도 활용될 수 있어요. 사용자의 선호도를 반영해 관련 이미지를 추천하는 데 큰 역할을 할 수 있죠.
하지만 CLIP을 사용할 때 주의해야 할 점도 있어요. 첫째로, 데이터의 품질이 매우 중요해요. CLIP은 학습 데이터에 따라 성능이 크게 달라질 수 있거든요. 또한, 특정 텍스트와 이미지 간의 연관성이 없는 경우, 잘못된 분류가 발생할 수 있어요. 따라서, 모델을 실제 환경에 적용하기 전에 충분한 검증이 필요해요.
마지막으로, CLIP은 강력한 도구지만, 모든 문제를 해결할 수 있는 만능은 아니에요. 항상 다른 모델과 비교 검토하고, 상황에 맞는 적절한 모델을 선택하는 것이 중요하답니다.
**Q1: CLIP은 어떤 용도로 사용되나요?**
A1: CLIP은 주로 이미지와 텍스트를 연결하는 데 사용되며, 이미지 검색 엔진, 콘텐츠 추천 시스템, 자동 이미지 태깅 등 다양한 분야에서 활용될 수 있어요. 특히, 텍스트 기반의 검색 쿼리에 대해 관련 이미지를 찾는 데 뛰어난 성능을 보여줘요.
**Q2: CLIP의 학습 과정은 어떻게 되나요?**
A2: CLIP은 콘트라스트 러닝이라는 기법을 사용해 학습해요. 이미지와 텍스트의 쌍을 통해 서로의 관계를 학습하며, 이를 통해 두 개체 간의 유사도를 측정할 수 있는 모델을 만들어내죠. 학습 데이터의 품질이 성능에 큰 영향을 미치기 때문에, 신뢰할 수 있는 데이터셋을 사용하는 것이 중요해요.
**Q3: CLIP을 사용할 때의 주의사항은 무엇인가요?**
A3: CLIP을 사용할 때는 데이터의 품질과 관련성을 항상 고려해야 해요. 잘못된 데이터나 관련성이 낮은 이미지와 텍스트 쌍을 사용하면, 부정확한 결과를 초래할 수 있어요. 또한, CLIP이 모든 상황에 적합한 모델은 아니므로, 다른 모델과 비교해 적절한 선택이 필요해요.
---
CLIP, 텍스트, 이미지 연결 · 주요 포인트 3
## CLIP의 활용 사례와 주의사항
CLIP의 활용 사례는 무궁무진해요. 예를 들어, 이미지 검색 엔진에 적용할 수 있어요. 사용자가 특정 텍스트를 입력하면, 해당 텍스트와 가장 유사한 이미지를 찾을 수 있도록 도와주는 거죠. 또한, 소셜 미디어에서의 콘텐츠 추천 시스템에도 활용될 수 있어요. 사용자의 선호도를 반영해 관련 이미지를 추천하는 데 큰 역할을 할 수 있죠.
하지만 CLIP을 사용할 때 주의해야 할 점도 있어요. 첫째로, 데이터의 품질이 매우 중요해요. CLIP은 학습 데이터에 따라 성능이 크게 달라질 수 있거든요. 또한, 특정 텍스트와 이미지 간의 연관성이 없는 경우, 잘못된 분류가 발생할 수 있어요. 따라서, 모델을 실제 환경에 적용하기 전에 충분한 검증이 필요해요.
마지막으로, CLIP은 강력한 도구지만, 모든 문제를 해결할 수 있는 만능은 아니에요. 항상 다른 모델과 비교 검토하고, 상황에 맞는 적절한 모델을 선택하는 것이 중요하답니다.
**Q1: CLIP은 어떤 용도로 사용되나요?**
A1: CLIP은 주로 이미지와 텍스트를 연결하는 데 사용되며, 이미지 검색 엔진, 콘텐츠 추천 시스템, 자동 이미지 태깅 등 다양한 분야에서 활용될 수 있어요. 특히, 텍스트 기반의 검색 쿼리에 대해 관련 이미지를 찾는 데 뛰어난 성능을 보여줘요.
**Q2: CLIP의 학습 과정은 어떻게 되나요?**
A2: CLIP은 콘트라스트 러닝이라는 기법을 사용해 학습해요. 이미지와 텍스트의 쌍을 통해 서로의 관계를 학습하며, 이를 통해 두 개체 간의 유사도를 측정할 수 있는 모델을 만들어내죠. 학습 데이터의 품질이 성능에 큰 영향을 미치기 때문에, 신뢰할 수 있는 데이터셋을 사용하는 것이 중요해요.
**Q3: CLIP을 사용할 때의 주의사항은 무엇인가요?**
A3: CLIP을 사용할 때는 데이터의 품질과 관련성을 항상 고려해야 해요. 잘못된 데이터나 관련성이 낮은 이미지와 텍스트 쌍을 사용하면, 부정확한 결과를 초래할 수 있어요. 또한, CLIP이 모든 상황에 적합한 모델은 아니므로, 다른 모델과 비교해 적절한 선택이 필요해요.
---
CLIP, 텍스트, 이미지 연결 · 핵심 장면 1
CLIP의 기본 개념
CLIP은 "Contrastive Language–Image Pre-training"의 약자로, 이미지와 텍스트 간의 관계를 학습하는 딥러닝 모델이에요. 이 모델은 텍스트와 이미지를 동시에 입력받아, 이 둘을 임베딩 벡터 공간에서 특정한 포인트로 맵핑해요. 예를 들어, 고양이 이미지를 입력하면, 이를 고양이에 해당하는 벡터로 변환하고, "고양이", "강아지", "차" 같은 텍스트를 입력하면 각각의 텍스트도 벡터로 변환되죠.
이렇게 변환된 벡터들끼리의 유사도를 계산하면, 가장 유사한 텍스트를 찾아낼 수 있어요. 예를 들어, 고양이 이미지와 "고양이"라는 텍스트의 유사도가 높다면, 해당 이미지는 "고양이"라고 분류할 수 있는 거죠. 이 방식은 기존의 이미지 분류 방식, 즉 수천 장의 레이블된 이미지를 준비해야 했던 수고를 덜어주는데요. CLIP은 미리 정의된 클래스에 구애받지 않고, 다양한 텍스트 프롬프트를 통해 이미지를 분석할 수 있는 유연성을 제공해요.
CLIP, 텍스트, 이미지 연결 · 실전 화면 2
CLIP의 작동 방식
CLIP의 작동 방식은 크게 두 가지로 나눌 수 있어요. 첫 번째는 이미지 인코딩이고, 두 번째는 텍스트 인코딩이에요. 이미지 인코딩은 주어진 이미지를 CNN(Convolutional Neural Network)이나 비전 트랜스포머를 이용해 임베딩 벡터로 변환해요. 예를 들어, 고양이 사진을 입력하면, 이를 512 차원의 벡터로 변환하게 되죠.
반면, 텍스트 인코딩은 주어진 텍스트를 트랜스포머 모델을 통해 처리해요. 텍스트는 시작 토큰과 종료 토큰을 붙인 후, 이를 트랜스포머의 셀프 어텐션 메커니즘을 통해 변환해요. 이렇게 변환된 텍스트도 역시 512 차원의 벡터로 만들어지죠. 최종적으로 이미지와 텍스트는 동일한 벡터 공간에 위치하게 되며, 이 둘 사이의 유사도를 비교할 수 있게 돼요.
이 과정에서 중요한 점은, 이미지와 텍스트가 잘 매치되도록 학습하는 과정이에요. 이를 위해 CLIP은 콘트라스트 러닝을 활용해, 이미지와 텍스트 쌍을 통해 서로를 더욱 잘 이해하게 만들죠. 이 방법 덕분에 CLIP은 다양한 이미지와 텍스트 조합에 대해 유연하게 대응할 수 있어요.
CLIP, 텍스트, 이미지 연결 · 주요 포인트 3
CLIP의 활용 사례와 주의사항
CLIP의 활용 사례는 무궁무진해요. 예를 들어, 이미지 검색 엔진에 적용할 수 있어요. 사용자가 특정 텍스트를 입력하면, 해당 텍스트와 가장 유사한 이미지를 찾을 수 있도록 도와주는 거죠. 또한, 소셜 미디어에서의 콘텐츠 추천 시스템에도 활용될 수 있어요. 사용자의 선호도를 반영해 관련 이미지를 추천하는 데 큰 역할을 할 수 있죠.
하지만 CLIP을 사용할 때 주의해야 할 점도 있어요. 첫째로, 데이터의 품질이 매우 중요해요. CLIP은 학습 데이터에 따라 성능이 크게 달라질 수 있거든요. 또한, 특정 텍스트와 이미지 간의 연관성이 없는 경우, 잘못된 분류가 발생할 수 있어요. 따라서, 모델을 실제 환경에 적용하기 전에 충분한 검증이 필요해요.
마지막으로, CLIP은 강력한 도구지만, 모든 문제를 해결할 수 있는 만능은 아니에요. 항상 다른 모델과 비교 검토하고, 상황에 맞는 적절한 모델을 선택하는 것이 중요하답니다.
[자주 묻는 질문]
CLIP은 어떤 용도로 사용되나요?
CLIP은 주로 이미지와 텍스트를 연결하는 데 사용되며, 이미지 검색 엔진, 콘텐츠 추천 시스템, 자동 이미지 태깅 등 다양한 분야에서 활용될 수 있어요. 특히, 텍스트 기반의 검색 쿼리에 대해 관련 이미지를 찾는 데 뛰어난 성능을 보여줘요.
CLIP의 학습 과정은 어떻게 되나요?
CLIP은 콘트라스트 러닝이라는 기법을 사용해 학습해요. 이미지와 텍스트의 쌍을 통해 서로의 관계를 학습하며, 이를 통해 두 개체 간의 유사도를 측정할 수 있는 모델을 만들어내죠. 학습 데이터의 품질이 성능에 큰 영향을 미치기 때문에, 신뢰할 수 있는 데이터셋을 사용하는 것이 중요해요.
CLIP을 사용할 때의 주의사항은 무엇인가요?
CLIP을 사용할 때는 데이터의 품질과 관련성을 항상 고려해야 해요. 잘못된 데이터나 관련성이 낮은 이미지와 텍스트 쌍을 사용하면, 부정확한 결과를 초래할 수 있어요. 또한, CLIP이 모든 상황에 적합한 모델은 아니므로, 다른 모델과 비교해 적절한 선택이 필요해요.



