게시글 삭제
정말 삭제하시겠습니까?
AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini
[주요 목차]
Foundation Model의 개념과 중요성
데이터와 아키텍처가 모델 성능에 미치는 영향
모델 학습 비용과 최적화 방법
안녕하세요! 오늘은 AI 모델 학습에 대한 흥미로운 이야기를 해볼게요. 특히, Foundation Model과 관련하여 학습 비용이 얼마나 드는지, 그리고 이러한 모델들이 어떻게 만들어지는지를 다룰 예정인데요. AI 기술이 빠르게 발전하면서, 기본적인 모델을 이해하는 것이 점점 더 중요해지고 있거든요. 이 글을 통해 여러분은 Foundation Model의 개념, 데이터와 아키텍처의 관계, 그리고 모델 학습에 필요한 비용과 최적화 방법에 대해 깊이 이해할 수 있을 거예요. 그럼 시작해볼까요?
 AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 본문 이미지 1
AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 본문 이미지 1
Foundation Model의 개념과 중요성
Foundation Model이란 GPT-4, Gemini와 같은 대규모 AI 모델을 의미해요. 이 모델들은 다양한 데이터로 학습되어 있기 때문에 특정 작업에 대해 뛰어난 성능을 발휘할 수 있죠. 이러한 모델을 학습하기 위해서는 대량의 데이터가 필요하고, 그 데이터는 모델이 학습하는 데 있어 가장 중요한 요소 중 하나입니다.
Foundation Model의 학습 과정은 크게 사전 훈련과 사후 훈련으로 나눌 수 있는데요. 사전 훈련에서는 대규모의 비정형 데이터를 사용해 모델이 일반적인 패턴을 학습하게 하고, 사후 훈련에서는 특정 도메인에 맞는 데이터로 모델을 세부 조정합니다. 이렇게 다양한 단계를 거치면서 모델의 성능이 극대화될 수 있어요.
이런 모델들은 자연어 처리, 이미지 인식 등 여러 분야에서 활용되고 있는데, 그만큼 많은 기업들이 경쟁적으로 이 기술을 발전시키고 있습니다. 그래서 이러한 모델을 이해하고 활용하는 것이 중요하죠. 특히 AI 엔지니어링의 기본 개념을 아는 것이 향후 AI 프로젝트를 성공적으로 이끌어가는 데 큰 도움이 됩니다.
 AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 주요 포인트 2
AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 주요 포인트 2
데이터와 아키텍처가 모델 성능에 미치는 영향
모델의 성능은 사용하는 데이터와 아키텍처에 크게 의존해요. 예를 들어, OpenAI와 구글은 웹에서 수집한 대량의 데이터를 사용해 모델을 훈련한 결과, 뛰어난 성능을 발휘하고 있습니다. 특히, 커먼 크롤 데이터를 활용하여 다양한 언어와 주제에 대한 정보를 학습하게 되죠. 하지만, 데이터 출처가 불투명한 최신 모델들은 비판을 피하기 위해 데이터 공개를 꺼리는 경향이 있습니다.
데이터의 질이 좋다면, 모델의 성능도 향상될 수 있어요. 예를 들어, 영어로 된 데이터가 많은 모델은 영어 질문에 대해 높은 정확도로 답변할 수 있습니다. 반면, 데이터가 부족한 언어의 경우 성능이 떨어질 수밖에 없죠. 예를 들어, 힌디어나 베트남어 같은 언어는 영어에 비해 훨씬 낮은 정확도를 보이기도 해요.
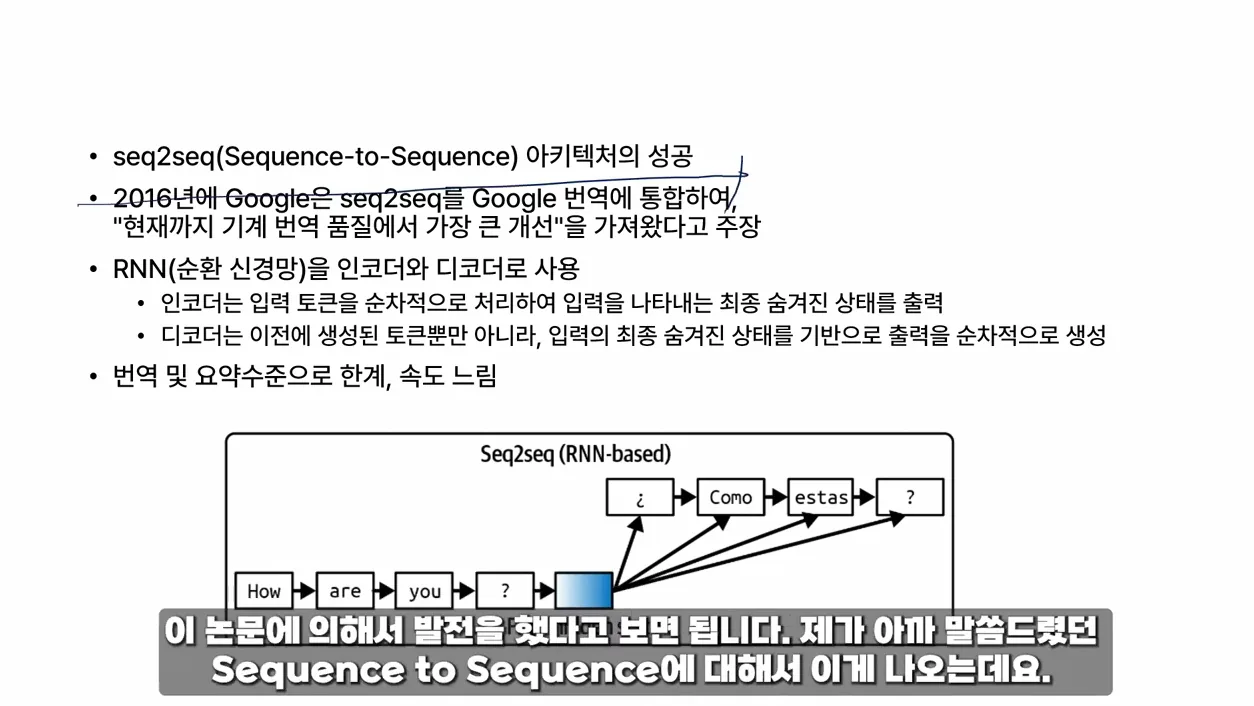
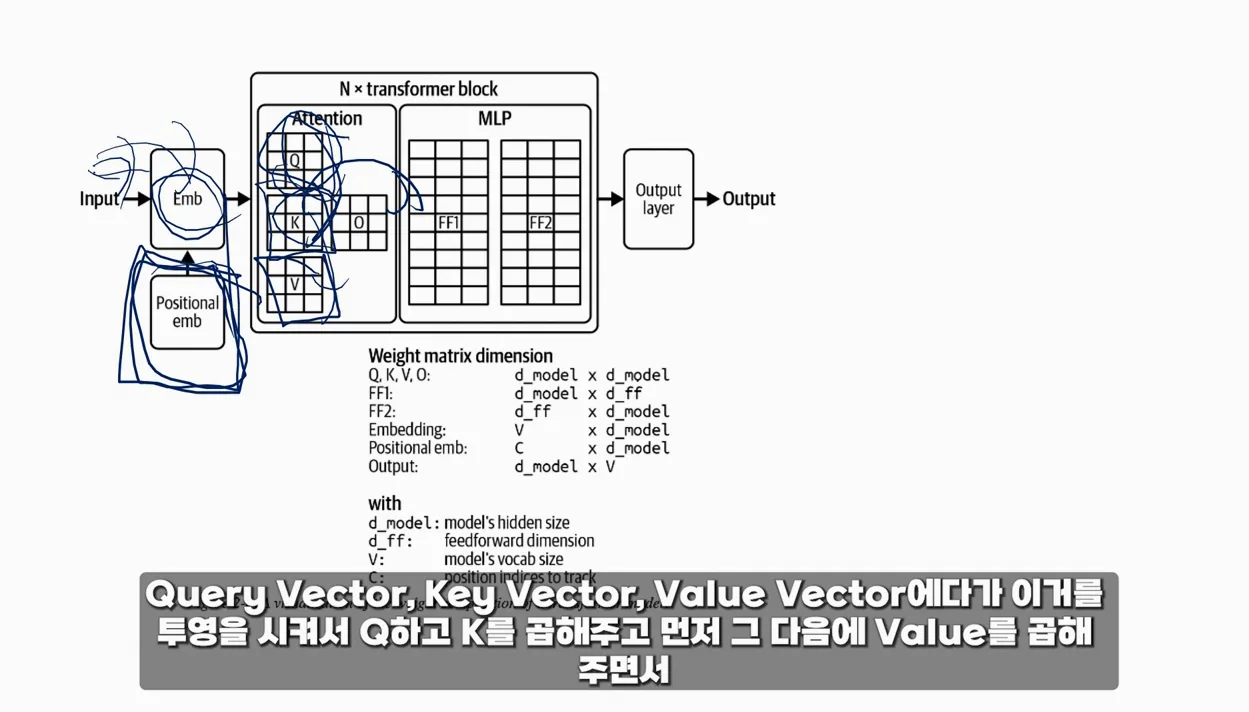
아키텍처 또한 모델 성능에 영향을 미치는 중요한 요소입니다. 최근에는 트랜스포머 아키텍처가 많이 사용되는데, 이는 입력 데이터를 동시에 처리할 수 있는 구조로 되어 있어 효율적이고 빠른 학습이 가능합니다. 이러한 아키텍처를 통해 모델이 더 많은 데이터를 더 빠르게 처리할 수 있게 되고, 결과적으로 성능이 개선됩니다.
 AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 현장 스냅 3
AI 모델 하나 학습하는데 60억원?! | 1. Foundation Model 학습 #aiengineering #트랜스포머 #gemini · 현장 스냅 3
모델 학습 비용과 최적화 방법
AI 모델을 학습하는 비용은 상당히 높은 편이에요. 예를 들어, GPT-3 모델을 학습하는 데 드는 비용은 약 60억 원에서 70억 원에 달한다고 알려져 있습니다. 이러한 비용은 주로 필요한 계산 리소스와 데이터 수집, 처리 과정에서 발생하는 비용 때문이에요. 특히, 대규모 GPU 서버를 운영해야 하므로 초기 투자 비용이 많이 들죠.
모델 최적화를 위해서는 여러 가지 방법이 존재합니다. 일반적으로, 모델의 성능을 90% 이상 끌어올리기 위해서는 많은 시간과 자원이 필요해요. 따라서 기업들은 성능 개선을 위한 다양한 방법을 연구하고 있습니다. 예를 들어, 파인 튜닝을 통해 특정 도메인에 맞는 데이터를 추가로 학습시켜 모델의 성능을 높일 수 있습니다. 이러한 과정은 모델의 활용도를 높이고, 실제 애플리케이션에서의 품질을 개선하는 데 큰 도움이 됩니다.
결론적으로, AI 모델의 학습 과정은 매우 복잡하고 비용이 많이 드는 작업이지만, 그만큼 효과적인 결과를 가져올 수 있는 기회도 많아요. AI 기술이 발전함에 따라 이러한 모델이 더욱 중요해질 것이므로, 이에 대한 이해는 필수적입니다.
[자주 묻는 질문]
Foundation Model이란 무엇인가요?
Foundation Model은 GPT-4나 Gemini와 같은 대규모 AI 모델을 의미해요. 이러한 모델들은 다양한 데이터로 학습되어 특정 작업에 대해 뛰어난 성능을 발휘합니다. 모델의 학습 과정은 사전 훈련과 사후 훈련으로 나뉘며, 각각의 과정에서 데이터의 질이 중요합니다.
AI 모델 학습 비용은 얼마나 되나요?
AI 모델 학습 비용은 매우 높은 편이에요. 예를 들어, GPT-3 모델을 학습하는 데 비용이 약 60억 원에서 70억 원에 달한다고 알려져 있습니다. 이러한 비용은 주로 계산 리소스와 데이터 수집, 처리 과정에서 발생합니다.
왜 데이터와 아키텍처가 모델 성능에 중요한가요?
데이터와 아키텍처는 모델 성능에 직접적인 영향을 미칩니다. 양질의 데이터는 모델의 학습 효율성을 높이고, 적절한 아키텍처는 데이터를 빠르게 처리할 수 있게 해주기 때문입니다. 따라서 이 두 요소는 모델 성능을 극대화하는 데 필수적입니다.



