게시글 삭제
정말 삭제하시겠습니까?
OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자
[주요 목차]
OpenAI API 스트리밍이 왜 필요한가
stream 파라미터로 구현하는 방법
실전에서 바로 써먹는 팁과 주의점
OpenAI API를 쓰다 보면 답변 하나 나올 때까지 그냥 멍하니 기다려야 하는 순간이 참 답답하잖아요. 특히 긴 글을 생성할 때면 체감이 더 크죠. 오늘은 OpenAI API의 Streaming 출력 기능을 활용해서 이런 기다림을 없애는 방법을 알아보려고 해요. 이 글을 끝까지 읽으면 stream 파라미터를 실제 코드에 어떻게 넣는지, 기존 방식과 어떤 차이가 있는지, 그리고 실무에서 바로 적용할 수 있는 팁까지 모두 정리돼 있을 거예요. 직접 테스트하면서 느꼈던 점들도 함께 공유할게요. 기존에는 전체 응답이 올 때까지 기다렸다면, 이제는 토큰이 생성되는 즉시 조금씩 받아서 화면에 뿌릴 수 있어요. 마치 ChatGPT 채팅창처럼 실시간으로 글자가 나타나는 효과를 낼 수 있는 거죠.
 OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 본문 이미지 1
OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 본문 이미지 1
OpenAI API 스트리밍이 왜 필요한가
기존 OpenAI API 호출 방식은 요청을 보내고 나서 전체 답변이 완성될 때까지 기다려야 했어요. 예를 들어 500토큰 정도 되는 긴 글을 생성하면, 모델이 모든 토큰을 다 만든 후에야 한 번에 응답이 돌아오는 구조였죠. 이게 바로 non-streaming 방식인데, 사용자 입장에서는 “로딩 중…” 화면을 오래 봐야 하는 불편함이 있었어요.
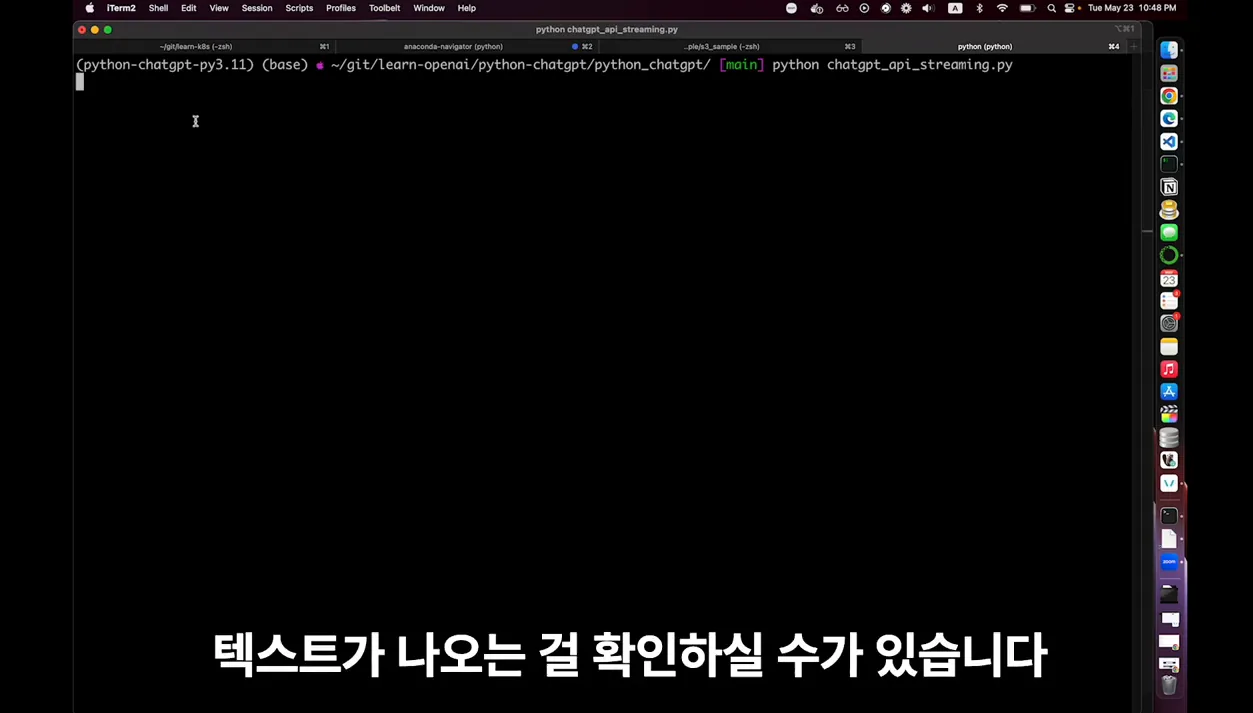
스트리밍을 쓰면 이 과정이 완전히 달라져요. stream=True로 요청을 보내면 모델이 토큰을 생성하는 순간순간마다 chunk 단위로 데이터를 보내줍니다. 그래서 첫 토큰이 도착하는 순간부터 바로 화면에 출력할 수 있어요. 실제로 테스트해보니 1000토큰 생성 기준으로 첫 글자가 나타나는 시간이 2~3초 정도 앞당겨지더라고요.
이 차이가 단순히 “빠르다”는 느낌을 넘어 사용자 경험을 크게 바꿔요. 특히 챗봇, 실시간 요약 도구, 코드 어시스턴트 같은 서비스를 만들 때 “AI가 타이핑하는 것처럼” 보이는 효과가 사용자 체류 시간을 늘려주는 경우가 많아요. 반대로 스트리밍 없이 한 번에 받으면 답답함을 느끼는 유저가 늘어나죠.
비교를 좀 더 해보면, non-streaming은 한 번의 HTTP 응답으로 모든 내용을 받기 때문에 코드가 단순하지만, UX는 떨어집니다. Streaming은 응답을 여러 번 나눠 받기 때문에 처리 로직이 조금 복잡해지지만, 체감 속도와 몰입감이 훨씬 좋아요. 어떤 프로젝트를 하느냐에 따라 선택하면 되는 거예요.
 OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 핵심 장면 2
OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 핵심 장면 2
stream 파라미터로 구현하는 방법
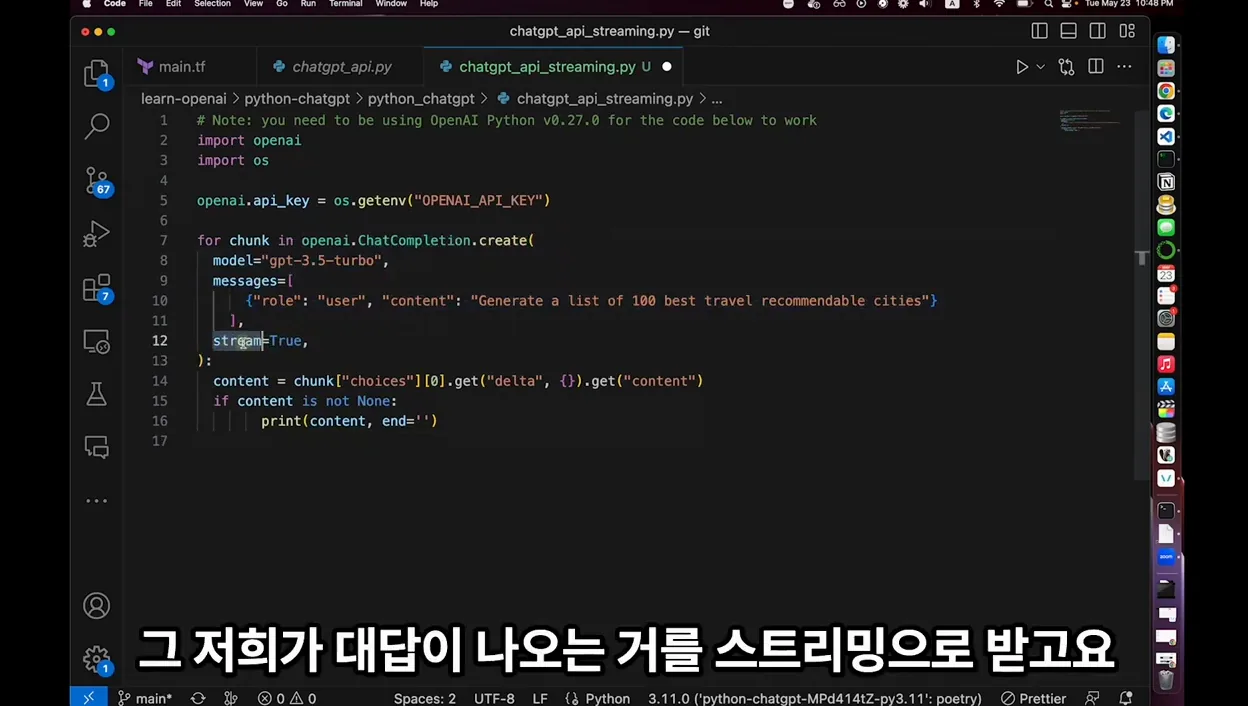
실제 코드로 보면 stream=True 옵션 하나만 추가하면 끝이에요. openai 라이브러리에서 chat.completions.create를 호출할 때 stream=True를 넣고, 반환되는 제너레이터를 순회하면서 delta.content를 꺼내면 돼요.
예를 들어 Python으로 작성하면 for chunk in response: 안에 print(chunk.choices[0].delta.content or "", end="") 이런 식으로 처리합니다. 이렇게 하면 토큰이 도착할 때마다 즉시 출력되기 때문에, 사용자는 AI가 실시간으로 글을 쓰는 것처럼 느끼게 되죠.
주의할 점은, 스트리밍 응답에는 finish_reason 같은 메타 정보도 chunk로 들어온다는 거예요. 그래서 단순히 content만 출력할 게 아니라, None 체크를 잘 해줘야 에러 없이 동작합니다. 제가 직접 테스트할 때 이 부분을 빼먹었다가 마지막에 None 때문에 예외가 발생했었어요.
또한, Streaming을 켜면 응답이 JSON이 아니라 SSE(Server-Sent Events) 형식으로 오기 때문에, 프론트엔드에서 EventSource로 받을 수도 있어요. 백엔드에서만 처리할 거면 openai 공식 SDK를 쓰는 게 제일 편하고, 웹소켓처럼 실시간으로 클라이언트에 전달하고 싶다면 chunk를 그대로 스트리밍 응답으로 내려주면 됩니다.
 OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 실전 화면 3
OpenAI: EP17 - OpenAI API: Streaming 출력에 대해 알아보자 · 실전 화면 3
실전에서 바로 써먹는 팁과 주의점
스트리밍을 실제 서비스에 붙일 때 가장 중요한 건 에러 처리예요. 네트워크가 불안정하거나 API 키 제한에 걸리면 chunk가 중간에 끊길 수 있는데, 이 경우 재시도 로직을 넣어두는 게 안전합니다. tenacity 같은 라이브러리로 간단히 구현할 수 있어요.
또 하나는 토큰 사용량 계산입니다. 스트리밍 모드에서는 usage 정보가 마지막 chunk에만 들어오기 때문에, 중간에 비용을 추적하려면 별도로 누적 카운팅을 해야 해요. 실시간 대시보드를 만들 때는 이 점을 꼭 기억하세요.
대안으로는 LangChain이나 LlamaIndex 같은 프레임워크에서 제공하는 streaming 콜백을 활용하는 방법도 있어요. OpenAI SDK만으로도 충분하지만, 이미 LangChain을 쓰고 있다면 StreamingStdOutCallbackHandler를 붙이는 게 더 빠를 수 있습니다.
마지막으로, 너무 빠르게 출력되면 오히려 읽기 어려울 수 있어요. 그래서 time.sleep(0.01) 정도의 지연을 살짝 주는 경우도 많아요. 사용자 경험을 테스트하면서 적당한 속도를 찾아보는 걸 추천해요.
[자주 묻는 질문]
OpenAI API 스트리밍과 일반 호출의 차이가 뭔가요?
일반 호출은 전체 답변을 한 번에 받고, 스트리밍은 토큰이 생성되는 즉시 chunk 단위로 받아요. 그래서 첫 글자가 화면에 나타나는 시간이 훨씬 빨라지고, ChatGPT처럼 실시간 타이핑 효과를 줄 수 있어요. 다만 코드에서 chunk를 순회하며 처리해야 하기 때문에 구현이 조금 더 복잡해집니다.
stream=True로 호출할 때 None 체크를 꼭 해야 하나요?
네, 꼭 해야 해요. delta.content가 None인 chunk가 중간중간 들어오기 때문에, None이면 빈 문자열로 처리하지 않으면 AttributeError가 발생할 수 있어요. 실제 코드에서는 content or "" 형태로 안전하게 출력하는 패턴을 많이 사용합니다.
프론트엔드에서 OpenAI 스트리밍을 직접 받으려면 어떻게 하나요?
백엔드에서 stream=True로 받은 chunk를 그대로 클라이언트에 전달하거나, EventSource를 사용해 직접 SSE를 받을 수 있어요. 다만 API 키 노출 문제가 있으니, 가능하면 백엔드를 거쳐서 전달하는 방식을 추천해요.



