게시글 삭제
정말 삭제하시겠습니까?
문자열 다루기 2 | Rust언어 {no.121}
[주요 목차]
Rust에서 문자열 인덱싱이 안 되는 이유
스트링 슬라이싱으로 안전하게 자르기
chars()로 한 글자씩 순회하는 방법
러스트로 문자열을 다루다 보면 제일 먼저 부딪히는 게 인덱스로 접근하는 문법이 안 된다는 점이잖아요. 영어는 잘 되는데 한글 넣으면 갑자기 런타임 패닉이 뜨거나 컴파일 자체가 안 되니까 당황스럽죠. 실제로 “hello”에서 첫 글자만 빼려고 s[0] 했다가 에러 만나본 사람들 꽤 있어요. 이 글에서는 Rust 문자열 다루기에서 왜 인덱싱이 안 되고, 대신 어떻게 스트링 슬라이스를 써야 하는지, 그리고 chars()로 안전하게 한 글자씩 루프 도는 법까지 정리했어요. 영상 안 봐도 바로 따라 해볼 수 있게 예제와 주의사항을 모두 넣었으니, Rust 문자열 다루기 제대로 익히고 싶은 분들 끝까지 읽어보세요.
 문자열 다루기 2 | Rust언어 {no.121} · 주요 포인트 1
문자열 다루기 2 | Rust언어 {no.121} · 주요 포인트 1
Rust에서 문자열 인덱싱이 안 되는 이유
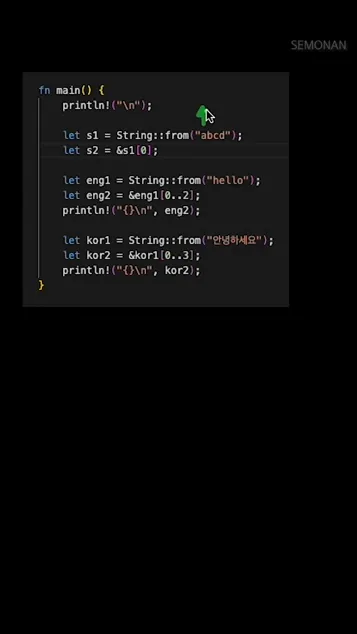
러스트가 문자열 인덱싱을 허용하지 않는 이유는 UTF-8 인코딩 방식 때문인데요. UTF-8은 한 글자가 1바이트부터 4바이트까지 가변 길이로 저장돼요. 영어·숫자는 1바이트, 한글은 3바이트, 이모지나 일부 문자는 4바이트가 될 수도 있죠.
그래서 “abcd”처럼 1바이트짜리 문자열만 있을 때는 s1[0]으로 접근해도 운 좋게 동작할 수 있지만, “안녕하세요”처럼 3바이트 문자가 섞이면 0번 인덱스가 문자의 시작 바이트가 아닐 가능성이 커요. 러스트는 이런 위험을 애초에 막기 위해 인덱스 접근 자체를 컴파일 에러로 처리합니다.
실제 사례를 보면, 초보자들이 가장 많이 하는 실수가 “한글 문자열에서 [0]으로 첫 글자를 꺼내려다 런타임 패닉”이에요. 러스트는 이런 실수를 미리 막아주는 언어 설계 철학을 가지고 있거든요. 대신 제공하는 게 바로 스트링 슬라이스 문법입니다.
 문자열 다루기 2 | Rust언어 {no.121} · 주요 포인트 2
문자열 다루기 2 | Rust언어 {no.121} · 주요 포인트 2
스트링 슬라이싱으로 안전하게 자르기
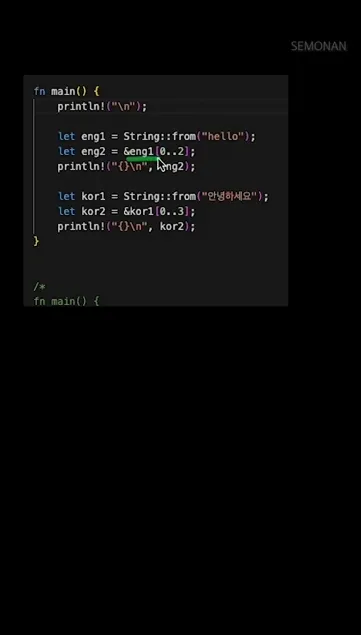
스트링 슬라이스는 &s[start..end] 형태로 사용해요. “hello”라는 문자열에서 처음 두 글자를 가져오고 싶다면 &eng1[0..2]라고 쓰면 “he”가 나옵니다. 여기서 중요한 점은 범위가 바이트 단위라는 거예요.
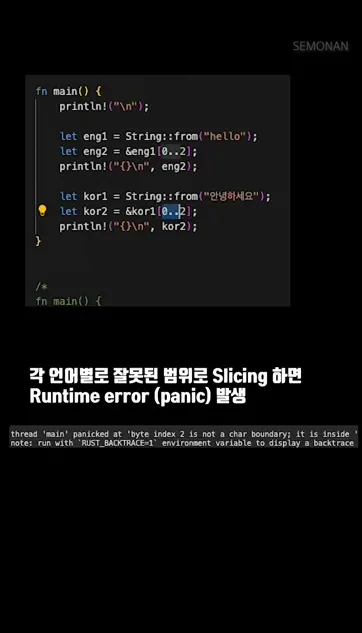
한글 “안녕하세요”를 슬라이스할 때는 반드시 3의 배수로 범위를 지정해야 해요. 0..3은 “안”, 0..6은 “안녕”이 됩니다. 만약 0..2처럼 중간을 자르면 런타임에 panic이 발생하죠. 실제로 이런 실수를 하면 프로그램이 바로 종료되기 때문에 운영 환경에서는 특히 조심해야 합니다.
비교해 보면, Go나 Python은 인덱싱이 편리한 대신 숨은 버그가 생기기 쉽고, 러스트는 조금 번거롭지만 안전성을 우선시하는 방식이에요. 실전에서는 슬라이스 범위를 직접 숫자로 쓰기보다는, chars()로 변환한 뒤 take()나 is_char_boundary() 같은 메서드를 활용하는 패턴이 더 안전합니다.
 문자열 다루기 2 | Rust언어 {no.121} · 참고 컷 3
문자열 다루기 2 | Rust언어 {no.121} · 참고 컷 3
chars()로 한 글자씩 순회하는 방법
문자열을 한 글자 단위로 순회하고 싶을 때는 .chars() 메서드를 쓰는 게 정석이에요. “hello”.chars()는 각 알파벳을 유니코드 문자 단위로 이터레이터로 반환합니다. 그래서 for c in s.chars() { ... } 형태로 쓰면 h, e, l, l, o가 차례로 출력되죠.
한글 “안녕하세요”도 마찬가지로 chars()를 쓰면 “안”, “녕”, “하”, “세”, “요”가 한 글자씩 제대로 나옵니다. 바이트를 신경 쓸 필요가 없어서 훨씬 직관적이죠. 만약 bytes()를 쓰면 한글 한 글자가 3바이트로 쪼개져서 의도치 않은 결과가 나올 수 있어요.
실무 팁으로는, 문자열 길이를 글자 수 기준으로 알고 싶을 때 chars().count()를 사용하고, 특정 위치의 문자를 안전하게 가져오고 싶을 때는 chars().nth(n)이나 chars().skip(n).next() 패턴을 활용하세요. 이렇게 하면 UTF-8 경계를 걱정할 필요 없이 깔끔하게 처리됩니다.
[자주 묻는 질문]
Rust에서 문자열 인덱싱이 안 되는 이유가 정확히 뭔가요?
UTF-8이 가변 길이 인코딩이기 때문입니다. 한 글자가 1~4바이트로 다르기 때문에 인덱스로 접근하면 중간 바이트를 잘못 읽을 위험이 있어요. 그래서 러스트는 컴파일 단계에서 아예 막아버립니다. 대신 스트링 슬라이스나 chars()를 사용해야 해요.
한글 문자열 슬라이스할 때 3바이트가 아닌 다른 숫자를 쓰면 어떻게 되나요?
런타임 패닉이 발생합니다. 예를 들어 “안녕하세요”에서 0..2처럼 3의 배수가 아닌 범위를 주면 “byte index 2 is not a char boundary”라는 에러와 함께 프로그램이 종료돼요. 항상 글자 경계를 지켜서 슬라이스해야 합니다.
chars()와 bytes()의 차이점을 간단히 알려주세요.?
chars()는 유니코드 한 글자 단위로 이터레이터를 만들고, bytes()는 실제 저장된 바이트 단위로 쪼갭니다. 한글을 다룰 때는 chars()를 써야 한 글자씩 제대로 처리되고, bytes()는 주로 바이너리 데이터나 저수준 조작에 사용됩니다.



