게시글 삭제
정말 삭제하시겠습니까?
파이썬 크롤링 기초 강좌 - 예제 1. 네이버 헤드라인 뉴스를 크롤링 해보자
[주요 목차]
📝 네이버 뉴스 크롤링 시작하기
🔍 리퀘스트(Requests) 라이브러리 이해하기
🥣 뷰티풀 수프(BeautifulSoup)로 HTML 분석하기
📰 헤드라인 뉴스 크롤링
🔄 여러 뉴스 제목 가져오기
안녕하세요, 프로그래밍에 관심 있는 여러분! 오늘은 Python과 BeautifulSoup을 활용하여 네이버 뉴스 헤드라인을 크롤링하는 방법에 대해 알아보겠습니다. 웹 크롤링은 자동화 작업의 핵심 기술로, 다양한 웹사이트에서 정보를 수집할 수 있는 강력한 도구입니다. 본 포스트에서는 웹 크롤링의 기초부터 실제 네이버 뉴스 데이터를 가져오는 과정까지 단계별로 설명드리겠습니다. 파이썬 기초 문법과 HTML 구조에 대한 기본적인 이해를 바탕으로, 여러분도 쉽게 따라 할 수 있을 것입니다.
📝 네이버 뉴스 크롤링 시작하기
네이버 뉴스 크롤링을 시작하기에 앞서, 왜 크롤링이 중요한지 잠시 알아보겠습니다. 웹 크롤링은 웹사이트에서 원하는 데이터를 자동으로 수집하는 기술로, 데이터 분석, 리서치, 뉴스 모니터링 등 다양한 분야에서 활용되고 있습니다. 특히 파이썬을 활용하면 비교적 간단한 코드로 강력한 크롤러를 만들 수 있습니다. 시작하기 전에 파이썬과 BeautifulSoup 라이브러리가 설치되어 있어야 하며, 네이버 뉴스 페이지의 HTML 구조를 대략적으로 파악하는 것이 좋습니다. 이제 본격적으로 크롤링을 시작해 보겠습니다.

🔍 리퀘스트(Requests) 라이브러리 이해하기
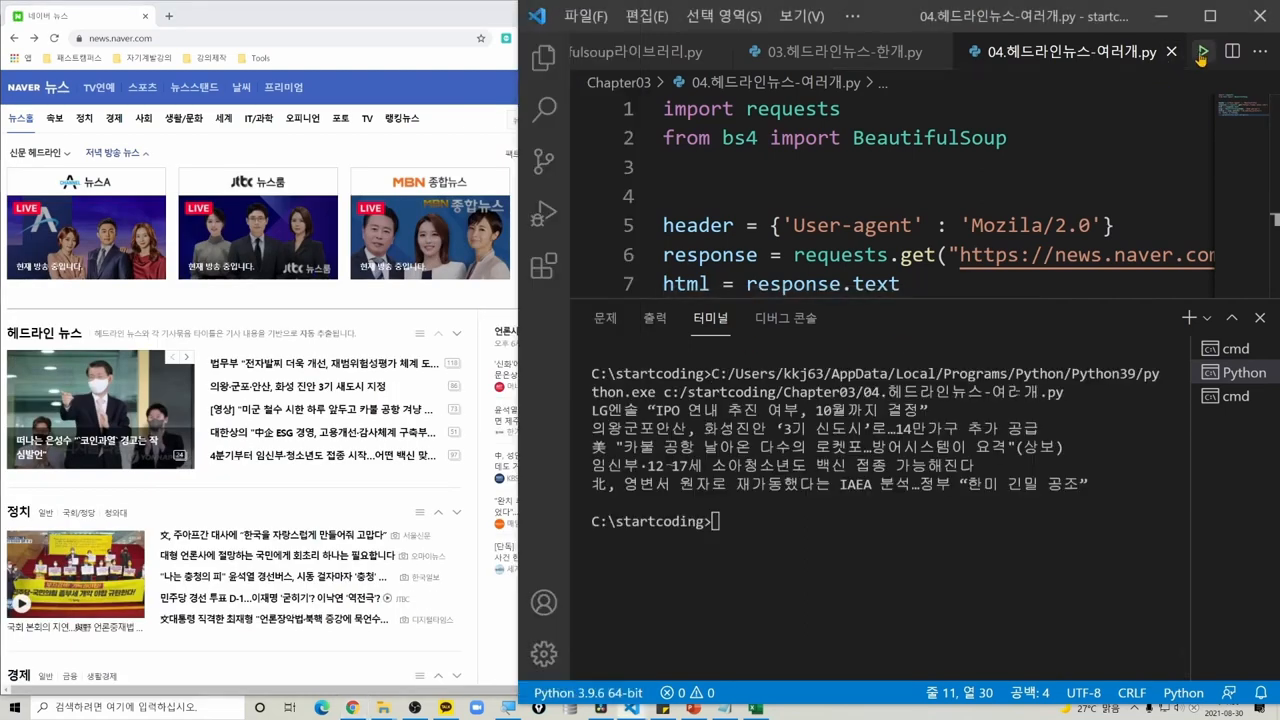
웹 크롤링의 첫 단계는 웹 페이지에 접근하는 것입니다. 파이썬의 Requests 라이브러리는 웹 서버에 HTTP 요청을 보내고 응답을 받는 과정을 손쉽게 처리해줍니다. 이 라이브러리는 마치 웹 브라우저처럼 서버에 GET, POST 요청을 보내며, 웹 페이지의 HTML 소스 코드를 가져올 수 있게 합니다. Requests 라이브러리를 사용하면 복잡한 네트워크 프로그래밍을 피할 수 있으며, 간단한 코드로 원하는 데이터를 가져올 수 있습니다. 설치는 pip install requests 명령어로 간단히 완료할 수 있습니다.

🥣 뷰티풀 수프(BeautifulSoup)로 HTML 분석하기
뷰티풀 수프(BeautifulSoup)는 HTML 및 XML 파일을 탐색하고, 파싱하며, 수정할 수 있는 파이썬 라이브러리입니다. 이 라이브러리를 사용하여 HTML 문서를 탐색하고, 원하는 태그나 속성을 쉽게 추출할 수 있습니다. HTML 문서 안에서 특정 요소를 찾기 위해 CSS 선택자나 태그 이름을 사용할 수 있으며, 이를 통해 보다 정교한 데이터 추출이 가능합니다. 설치는 pip install beautifulsoup4로 진행할 수 있고, HTML 파싱을 위해 from bs4 import BeautifulSoup을 사용합니다.
📰 헤드라인 뉴스 크롤링
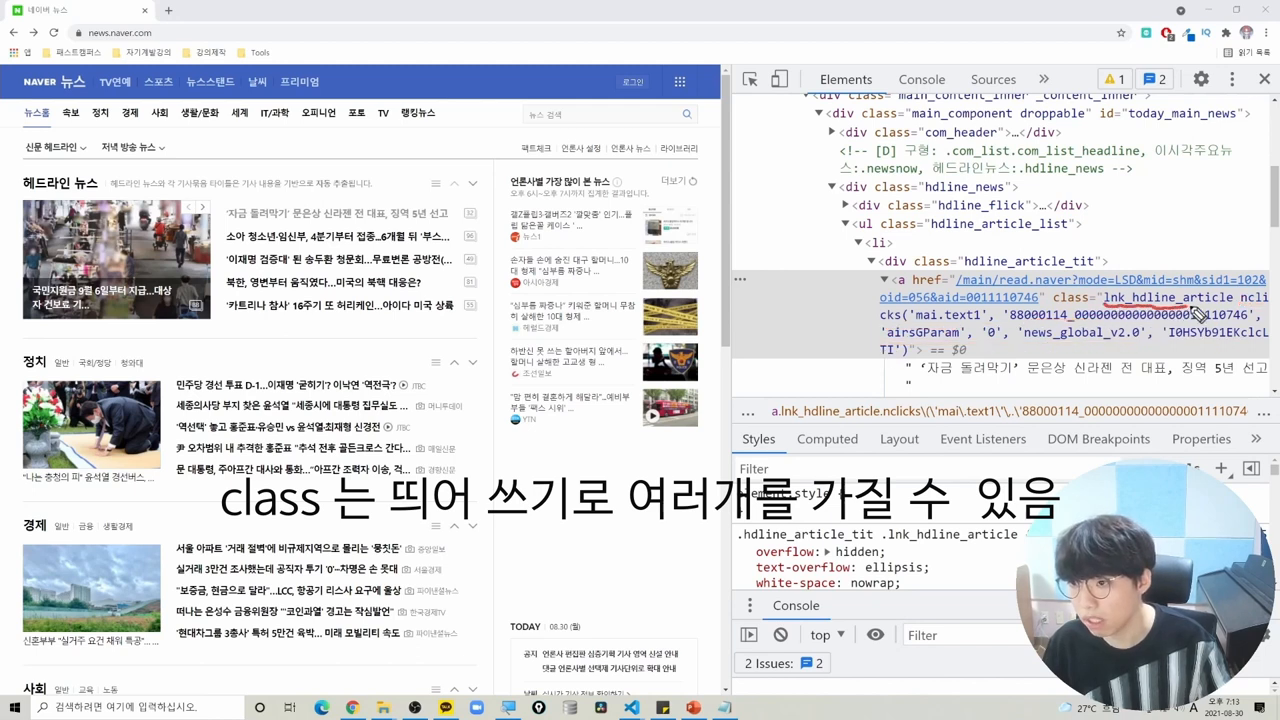
네이버 뉴스의 헤드라인을 크롤링하기 위해서는 HTML 구조를 분석하여 적절한 CSS 선택자를 통해 원하는 데이터를 가져와야 합니다. 먼저 네이버 뉴스 페이지의 HTML 소스코드를 Requests로 가져온 후, BeautifulSoup을 사용하여 HTML을 파싱합니다. 그런 다음, 헤드라인 뉴스에 해당하는 태그와 클래스 속성을 찾아내어 이를 기반으로 데이터를 추출합니다. 여기서는 soup.select() 메소드를 사용하여 CSS 선택자로 원하는 항목을 선택할 수 있습니다.
🔄 여러 뉴스 제목 가져오기
마지막 단계에서는 여러 개의 뉴스 제목을 한 번에 가져오는 방법을 알아봅니다. 앞서 배운 단일 뉴스 크롤링 방법을 확장하여, 여러 개의 뉴스 항목을 리스트 형태로 받아올 수 있습니다. 이를 위해 soup.select()를 사용하여 모든 관련 태그를 선택하고, 반복문을 통해 각 뉴스 제목을 순회하며 데이터를 추출합니다. 이렇게 수집된 데이터는 리스트에 저장하여 필요에 따라 파일로 저장하거나, 다른 데이터 분석 작업에 활용할 수 있습니다.



