게시글 삭제
정말 삭제하시겠습니까?
네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보)
[주요 목차]
네이버 증권 크롤링 준비물
네이버 증권 데이터 크롤링 방법
크롤링 후 데이터 처리 및 자동화
주식 투자에 관심이 많아지면서 실시간 주가 정보를 손쉽게 얻고 싶어하는 분들이 많거든요. 특히, 네이버 증권에서 제공하는 주식 데이터를 자동으로 크롤링하면 수작업으로 데이터를 입력하는 번거로움을 없앨 수 있어요. 이 글에서는 파이썬을 사용해 네이버 증권에서 실시간 주가 정보를 크롤링하는 방법을 단계별로 설명할 거예요. 이 과정을 통해 주식 종목 분석 엑셀을 자동화할 수 있는 기초를 다질 수 있을 거예요.
 네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 실전 화면 1
네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 실전 화면 1
네이버 증권 크롤링 준비물
먼저 크롤링을 시작하기 전에 필요한 준비물을 정리해볼게요. 가장 기본적으로 파이썬이 설치되어 있어야 하고, 크롤링에 필요한 라이브러리인 requests와 BeautifulSoup도 설치해야 해요. 이 두 라이브러리는 웹 페이지의 HTML 데이터를 가져오고, 이를 파싱하는 데 필수적이에요.
파이썬의 기초적인 문법, 즉 변수, 리스트, 반복문 등은 알고 있어야 해요. 만약 이 부분이 낯설다면, 파이썬 기초 강의를 듣고 오시는 것도 좋은 방법이에요. 또한, 크롤링에 대한 기초 지식이 필요하기 때문에, 기본적인 크롤링 방법에 대한 강의도 참고하면 좋겠죠.
이제 준비물이 갖춰졌다면, 본격적으로 네이버 증권 사이트를 분석해보는 단계로 넘어가야 해요. 크롤링할 데이터를 결정하고, 그 데이터가 포함된 HTML 태그를 찾아야 하거든요.
 네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 참고 컷 2
네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 참고 컷 2
네이버 증권 데이터 크롤링 방법
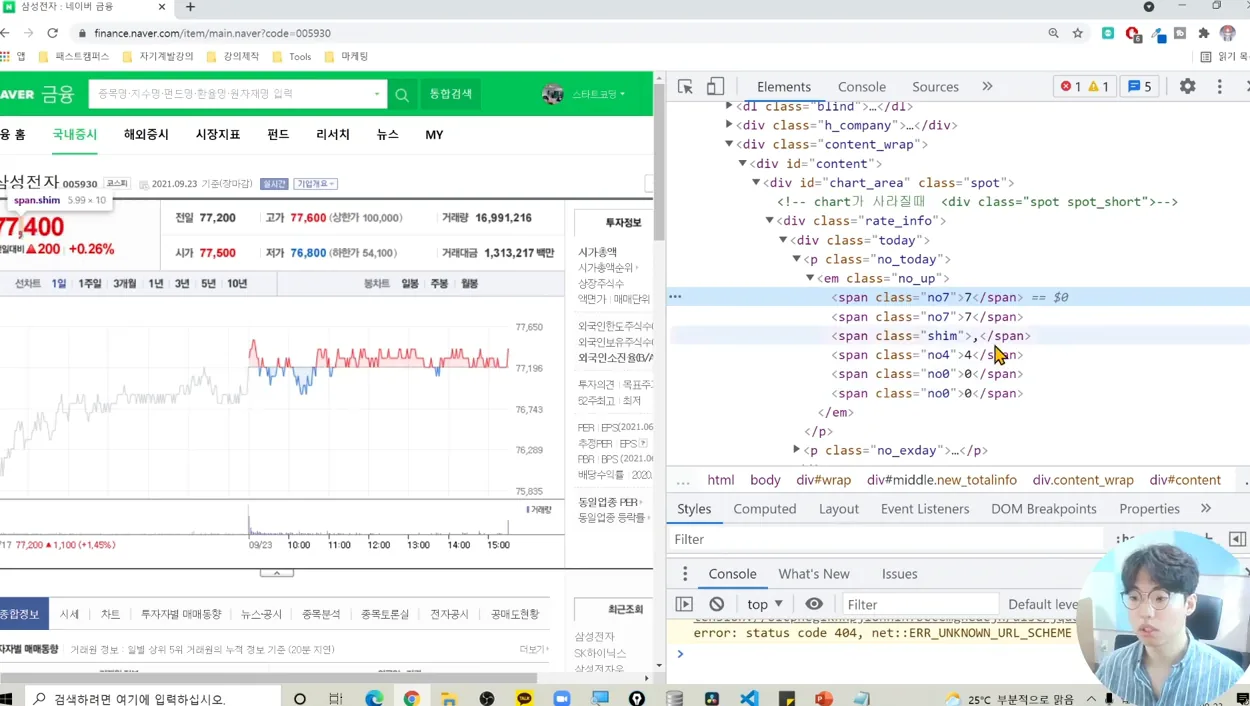
네이버 증권 사이트에 들어가서 원하는 주식, 예를 들어 삼성전자를 검색해보세요. 검색 결과 페이지에서 F12 키를 눌러 개발자 도구를 열고, 현재가 정보가 있는 HTML 요소를 찾아야 해요. 현재가는 보통 특정 ID나 클래스명으로 태그화 되어 있으니, 이를 잘 찾아야 해요.
삼성전자의 경우, ID가 now_val인 태그에서 현재가 정보를 가져올 수 있어요. 이 정보를 크롤링하기 위해서는 해당 URL에 종목 코드 파라미터를 추가해서 요청을 보내야 해요. 예를 들어, 삼성전자의 종목 코드는 005930이고, 이를 URL에 추가하면 특정 종목의 현재가 정보를 가져올 수 있게 되죠.
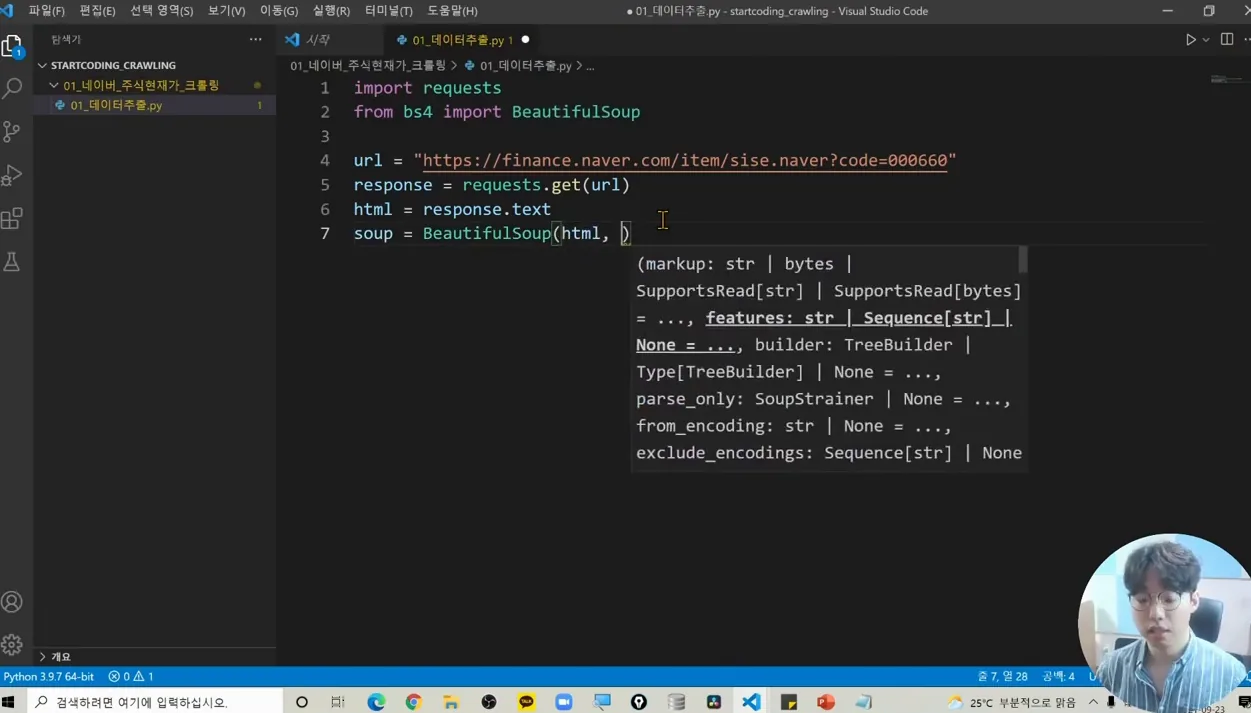
이제 본격적으로 코드를 작성해볼까요? 비주얼 스튜디오 코드나 다른 IDE를 열고, 새 프로젝트 폴더를 만들어주세요. 그 안에 Python 파일을 생성한 후 필요한 라이브러리를 임포트해야 해요. 예를 들어, 다음과 같은 코드를 시작으로 진행할 수 있어요:
```python import requests from bs4 import BeautifulSoup
url = 'https://finance.naver.com/item/main.nhn?code=005930' # 삼성전자 URL response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') current_price = soup.select_one('#now_val').text # 현재가 정보 추출 print(current_price) ```
이렇게 하면 삼성전자의 현재가 정보를 출력할 수 있게 되죠.
 네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 실전 화면 3
네이버 증권 주식 금융 데이터 크롤링 하는법 간단정리!! (1편 실시간 주가 정보) · 실전 화면 3
크롤링 후 데이터 처리 및 자동화
데이터를 여러 종목에 대해 크롤링하고 싶다면, 종목 코드를 리스트에 저장하고 반복문을 사용해 각각의 종목에 대해 크롤링을 수행해야 해요. 예를 들어, 삼성전자, SK하이닉스, 카카오의 종목 코드를 리스트로 만들어 반복문을 통해 각 종목의 현재가를 가져오는 코드를 작성할 수 있어요.
python
stock_codes = ['005930', '000660', '035720'] # 삼성전자, SK하이닉스, 카카오
for code in stock_codes:
url = f'https://finance.naver.com/item/main.nhn?code={code}'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
current_price = soup.select_one('#now_val').text
print(f'{code}의 현재가는 {current_price}입니다.')
이렇게 하면 각 종목의 현재가를 자동으로 출력할 수 있어요.
마지막으로, 이 데이터를 엑셀로 저장하고 싶다면, pandas 라이브러리를 활용하는 것도 좋은 방법이에요. 다음 영상에서는 엑셀에 데이터를 저장하는 방법도 다룰 예정이니, 기대해 주세요!
[자주 묻는 질문]
네이버 증권 주식 크롤링을 위해 어떤 라이브러리를 설치해야 하나요?
주식 크롤링을 위해서는 `requests`와 `BeautifulSoup` 라이브러리를 설치해야 해요. `requests`는 웹페이지의 HTML 데이터를 가져오는 데 사용되고, `BeautifulSoup`은 가져온 HTML 데이터를 파싱하는 데 유용해요. 이 두 라이브러리는 파이썬의 패키지 관리자인 pip를 통해 쉽게 설치할 수 있어요.
크롤링한 데이터를 엑셀로 저장하려면 어떻게 해야 하나요?
크롤링한 데이터를 엑셀로 저장하려면 `pandas` 라이브러리를 사용하는 것이 좋습니다. `pandas`는 데이터프레임을 엑셀 파일로 쉽게 변환해주는 기능을 제공해요. 크롤링한 데이터를 리스트나 데이터프레임으로 저장한 후, `to_excel()` 메서드를 사용하면 엑셀 파일로 저장할 수 있어요.
크롤링할 수 있는 다른 데이터는 무엇이 있나요?
네이버 증권 외에도 다양한 웹사이트에서 주식, 환율, 암호화폐 등 여러 금융 데이터를 크롤링할 수 있어요. 각 웹사이트의 HTML 구조에 따라 적절한 태그와 URL을 찾아주면 원하는 데이터를 가져올 수 있죠. 단, 사이트의 이용약관을 확인하고 크롤링이 허용되는지 확인하는 것이 중요해요.



