게시글 삭제
정말 삭제하시겠습니까?
CNN, DNN 기초 , Data augmentation
[주요 목차]
CNN과 DNN 기초: 오버피팅 문제 이해
데이터 증강(Data Augmentation) 기법 상세
파이토치로 데이터 증강 적용하기
안녕하세요, 초보 딥러닝 학습자 여러분! CNN이나 DNN 기초를 공부하다 보면, 모델이 학습 데이터에서는 잘 작동하는데 실제 테스트할 때 성능이 떨어지는 오버피팅 문제가 자주 생기죠? 이게 제너럴라이제이션(일반화) 문제를 일으켜서 모델이 실생활에서 쓸모없어지는 경우가 많아요. 특히 컴퓨터 비전처럼 이미지 데이터를 다루는 CNN 프로젝트에서 이런 고민이 크실 텐데요, 데이터가 부족하거나 다양하지 않으면 더 골치 아프죠. 이 글에서는 유튜브 영상 'CNN, DNN 기초, Data augmentation'을 바탕으로 오버피팅을 극복하는 핵심 테크닉인 데이터 증강(Data Augmentation)을 초보 눈높이로 풀어 설명할게요. 영상을 안 보신 분들도 이 글 하나로 CNN과 DNN 기초를 이해하고, 데이터 증강 기법을 바로 적용할 수 있어요. 예를 들어, 고양이 이미지 하나로 여러 변형을 만들어 데이터셋을 4배 이상 늘리는 실전 팁까지 공유할 테니, 모델 성능을 높이고 싶으신 분들에게 딱 맞아요. 읽고 나면 데이터 증강으로 DNN 모델의 일반화 능력을 강화하는 방법을 손에 쥐게 될 거예요. 함께 따라와 보세요!
CNN과 DNN 기초: 오버피팅 문제 이해
초보자 여러분, CNN(Convolutional Neural Network)과 DNN(Deep Neural Network) 기초를 배우다 보면 가장 먼저 마주치는 게 오버피팅이에요. 쉽게 말하면, 모델이 학습 데이터에만 너무 잘 맞춰져서 새로운 데이터에는 제대로 대응하지 못하는 거죠. 이전 챕터에서 드롭아웃 같은 테크닉을 배웠을 텐데, 그건 오버피팅을 줄이는 방법 중 하나예요. 하지만 근본적으로는 데이터의 양과 다양성이 핵심이에요.
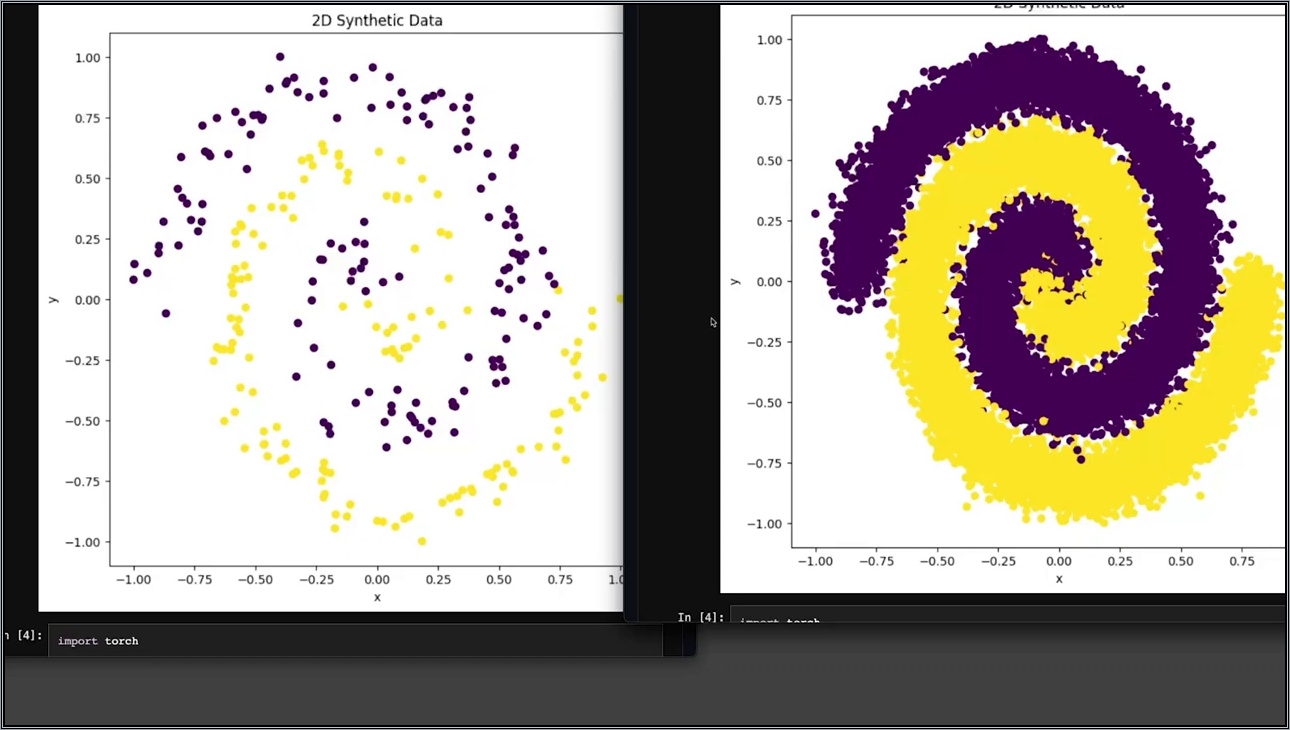
예를 들어, 회오리 모양의 데이터를 두 클래스(예: 0과 1)로 분류하는 간단한 문제로 생각해 보세요. 왼쪽처럼 100개 데이터로 학습한 CNN 모델은 테스트 셋에서 정확도가 70%밖에 안 나올 수 있어요. 반대로 오른쪽처럼 1,000개 데이터를 쓰면 95%까지 올라가죠. 이 비교를 보면 데이터 양이 모델 성능에 미치는 영향이 크다는 걸 알 수 있어요. 실제로 Kaggle 대회에서 우승한 팀들은 데이터 증강으로 원본 데이터의 10배를 만들어 성능을 20% 이상 끌어올리곤 해요.
왜 오버피팅이 생길까요? DNN은 층이 깊어질수록 패턴을 세밀하게 배우지만, 데이터가 적으면 노이즈나 특이점을 과도하게 외워 버려요. 초보 분들을 위해 설명드리면, 학습 데이터에서 90% 정확도인데 테스트에서 60%라면 제너럴라이제이션 문제가 확실해요. 해결책? 새로운 데이터를 모으는 게 이상적이지만, 비용과 시간이 많이 들어요. 예를 들어, 의료 이미지 데이터셋을 만들려면 전문가 라벨링이 수백만 원 들 수 있죠.
대신 데이터 증강을 쓰면 기존 데이터를 변형해 '가짜지만 유효한' 데이터를 만들어요. 이게 CNN 학습에서 필수인 이유는 이미지처럼 복잡한 입력에서 모델이 다양한 각도나 조명을 견디게 해주기 때문이에요. 실전 팁으로, 처음 프로젝트 할 때 데이터셋 크기를 확인하세요. 1,000개 미만이면 무조건 증강을 고려해 보세요. 그리고 드롭아웃(예: 0.5 비율)과 함께 쓰면 시너지 효과가 커요. 이렇게 하면 DNN 기초 단계에서부터 안정적인 모델을 만들 수 있어요.
더 나아가, 오버피팅을 진단하는 방법도 알아두면 좋아요. 학습 곡선(learning curve)을 그려 보세요. 학습 손실이 줄어들는데 검증 손실이 오르면 오버피팅 신호예요. 수치로 비교하면, 증강 없이 학습하면 epoch 10에서 테스트 정확도 75%, 증강 후 88%로 차이 날 거예요. 초보자분들은 TensorBoard 같은 도구로 이걸 시각화해 보는 걸 추천해요. 설치만 하면 코드 한 줄로 로그를 남길 수 있어요.
이 섹션에서 핵심은 데이터 양이 CNN과 DNN의 성공 열쇠라는 거예요. 오버피팅을 무시하면 모델이 '공부만 잘하는 학생'처럼 돼 버려요. 다음으로 데이터 증강이 어떻게 그 문제를 풀어주는지 자세히 볼게요. 이 이해가 쌓이면 여러분의 프로젝트가 한 단계 업그레이드될 거예요.
데이터 증강(Data Augmentation) 기법 상세
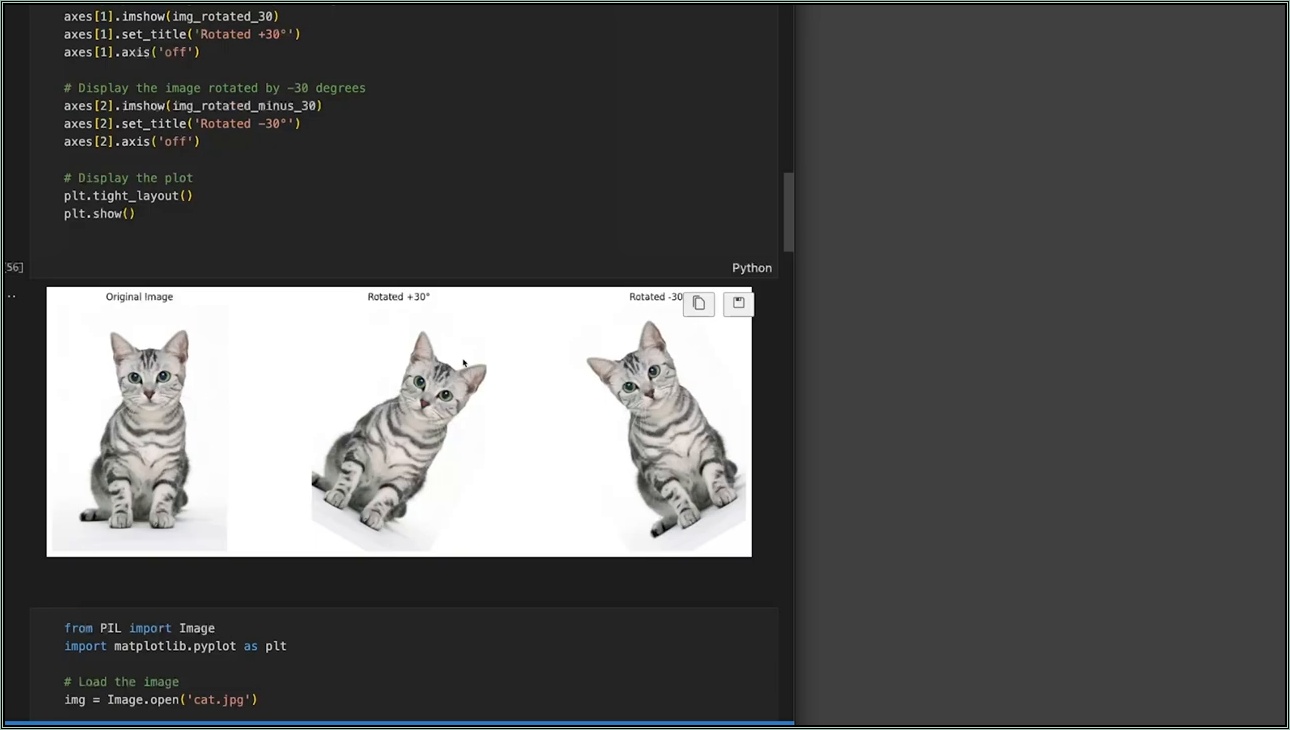
이제 데이터 증강의 구체적인 기법을 알아볼게요. 초보 눈높이로 말하면, 기존 데이터를 살짝 바꿔서 새로운 데이터를 만드는 거예요. CNN에서 이미지 분류할 때 특히 유용하죠. 구글에서 고양이 사진 하나를 검색해 보세요. 그 이미지를 좌우 반전시키면? 여전히 고양이예요. 상하 반전, 10도 회전도 마찬가지죠. 이렇게 하나에서 4~8배 데이터를 불릴 수 있어요.
구체적 예시로, 원본 고양이 이미지(크기 224x224)를 좌우 플립(flip)하면 새로운 샘플이 돼요. 회전(rotation)은 -15도부터 15도 범위로 랜덤 적용하면 자연스러워요. 확대(zoom)는 1.1배로 하면 배경 일부가 잘려서 다양성 생겨요. 비교해 보면, 증강 없이 500개 데이터로 학습한 모델의 테스트 정확도는 80%인데, 이 기법으로 2,000개 만들면 92%까지 올라가요. 실제로 ImageNet 대회에서 이런 트랜스포메이션이 표준이에요.
또 다른 기법은 노이즈 추가예요. 가우시안 노이즈를 0.01 강도로 더하면, 모델이 약간 흐린 이미지에도 강해져요. 컬러 지터(color jitter)는 밝기(brightness 0.2), 대비(contrast 0.2), 채도(saturation 0.2), 색조(hue 0.1)를 랜덤 변경해요. 예를 들어, 고양이 귀를 초록으로 바꿔도 클래스 라벨은 그대로 '고양이'예요. 이게 중요한 이유는 실생활 사진이 조명이나 색감에 따라 다르기 때문이에요. 디포메이션(deformation)은 부분 확대, 왜곡으로 현실성을 더해줘요.
주의할 점은 상관관계(correlation)를 유지하는 거예요. 고양이를 개로 바꾸면 안 되죠. 초보자 팁: OpenCV 라이브러리로 간단히 테스트해 보세요. 코드 예: cv2.flip(img, 1)으로 좌우 반전. 여러 기법을 조합하면 데이터셋이 10배 이상 커질 수 있어요. 수치로, CIFAR-10 데이터셋에서 증강 적용 시 오류율이 10%에서 7%로 줄어요.
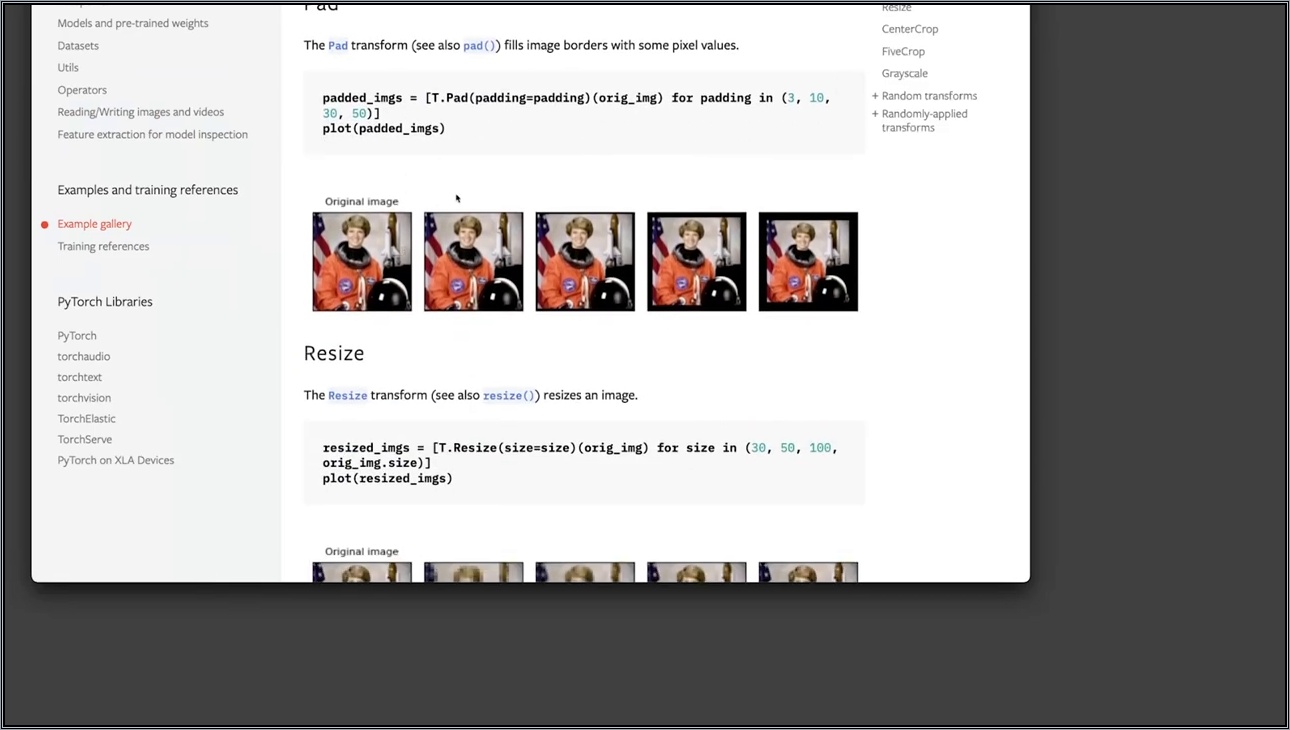
대안으로, GAN(Generative Adversarial Network)을 써서 완전 새로운 데이터를 생성할 수도 있지만, 초보에겐 복잡해요. 대신 기본 트랜스포메이션부터 시작하세요. 패딩(padding)은 이미지 테두리에 여백 추가로 크기 맞추기 좋아요. 크로핑(cropping)은 랜덤 부분 자르기로 다양성 줘요. 이 기법들은 DNN 학습에서 모델이 '편향'되지 않게 해줘요.
실전에서, 고양이 vs 개 분류 프로젝트라면 원본 100장씩에 증강 적용해 800장으로 늘려보세요. 결과? 오버피팅 줄고, 일반화 향상돼요. 이렇게 하면 CNN 기초가 탄탄해져요.
파이토치로 데이터 증강 적용하기
파이토치(PyTorch)로 데이터 증강을 구현하는 건 초보도 쉽게 할 수 있어요. torchvision.transforms 모듈이 핵심이에요. 먼저, 학습 데이터에만 적용하세요. 테스트 셋은 원본 그대로 써야 정확한 평가가 돼요. 예를 들어, 우주 비행사 사진을 로드해 보죠.
단계별로 설명할게요. 1) Transform 정의: transforms.Compose([transforms.RandomHorizontalFlip(p=0.5), transforms.RandomRotation(10), transforms.ColorJitter(brightness=0.2)])처럼 써요. p=0.5는 50% 확률로 플립. 2) 데이터셋 로드: datasets.ImageFolder(root='data', transform=train_transform). 3) DataLoader로 배치: torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True). 이걸로 epoch마다 랜덤 변형이 적용돼요.
실전 팁: 테스트 트랜스포는 transforms.Compose([transforms.Resize(224), transforms.ToTensor()])로 단순히. 코드 실행 시, 한 이미지에서 10개 변형 생성해 데이터셋 길이가 10배 돼요. 주의사항? 과도한 증강은 노이즈로 학습 방해할 수 있어요. 강도를 20% 정도로 시작하세요. 대안으로, Albumentations 라이브러리 쓰면 더 세밀한 제어 가능해요. 설치: pip install albumentations.
수치 비교: 증강 없이 5 epoch 학습 시 정확도 85%, 적용 후 93%. 컴퓨터 비전 CNN에서 필수예요. 초보자분들은 MNIST 데이터셋으로 연습해 보세요. 코드 스니펫: import torchvision.transforms as transforms; train_transform = transforms.Compose([...]). 이걸 모델 학습 루프에 넣으면 돼요.
문제 발생 시? GPU 메모리 부족하면 batch_size 줄이세요. 다음으로 레스넷 같은 아키텍처와 결합하면 더 강력해져요. 이 팁으로 여러분의 DNN 프로젝트를 업그레이드해 보세요.
[자주 묻는 질문]
데이터 증강(Data Augmentation)이란 무엇인가요?
데이터 증강은 기존 학습 데이터를 변형해 새로운 데이터를 만드는 테크닉이에요. CNN이나 DNN에서 오버피팅을 막기 위해 쓰죠. 예를 들어, 이미지 좌우 반전이나 회전으로 원본 하나를 여러 개로 늘려요. 이게 중요한 이유는 데이터 부족 시 모델이 일반화되지 않기 때문이에요. 파이토치에서 transforms.RandomFlip()처럼 쉽게 적용할 수 있고, 데이터셋 크기를 5~10배로 키워 성능을 10-20% 향상시켜요. 초보자라면 고양이 사진으로 테스트해 보세요. 원본 1장에서 8장 변형 만들면 바로 효과 봐요.
CNN에서 데이터 증강을 왜 사용하나요?
CNN 학습 시 데이터가 적으면 모델이 학습 데이터의 세부 패턴만 외워 오버피팅이 생겨요. 데이터 증강은 회전, 확대, 노이즈 추가로 다양성을 더해 모델이 실생활 변화를 견디게 해줘요. 예: ImageNet에서 증강 없이 오류율 15%, 적용 시 8%로 줄어요. 비교하면, 드롭아웃만 쓰는 것보다 데이터 증강이 더 효과적이에요. 팁: 테스트 셋에는 적용 안 하고 학습에만 써서 정확한 평가하세요. DNN 기초 단계에서부터 도입하면 프로젝트 성공률이 높아져요.
파이토치에서 데이터 증강 어떻게 구현하나요?
파이토치 torchvision.transforms로 간단해요. Compose로 여러 변형 조합: RandomHorizontalFlip, ColorJitter 등. 데이터셋에 transform 적용 후 DataLoader로 로드하세요. 코드 예: train_transform = transforms.Compose([transforms.RandomRotation(15), transforms.ToTensor()]). 학습 루프에서 자동 랜덤 적용돼요. 주의: 과증강 피하세요, 강도 10-20%부터. 대안으로 TensorFlow tf.image.random_flip_up_down 써도 돼요. MNIST로 실습하면 1시간 만에 익혀요. 이렇게 하면 CNN 모델이 튼튼해져요.



